Why - 数据质量
在数据处理过程中,可能会因为各种原因导致数据异常,数据处理链路上任意一个环节异常都可能导致最终数据异常,例如:
- 数据采集问题
- 数据丢失
- 数据重复
- 数据延迟
- 数据格式变动、不一致
- 数据处理程序问题
- 程序bug导致数据产出异常
- 基础设施问题导致程序运行异常
- 数据存储问题
- 磁盘问题导致丢数据
- 主重复制丢数据
因此需要一个标准来描述数据是否有异常,即数据质量。
What - 数据质量的六个维度
DAMA组织在这篇文档中从六个维度定义了数据质量:
- Completeness 完整性
- Uniqueness 唯一性
- Timeliness 时效性
- Validity 有效性
- Accuracy 精确性
- Consistency 一致性

1. Completeness 完整性
完整性表示数据是否完整,是否有缺失,可以用0-100%的数值表示。
案例:学校要求每位学生的家长完成问卷调查,其中包含一些信息包括:姓名、地址、联系方式、健康状况等。当数据分析师需要分享联系方式这个信息时,发现300名学生中有294名填写了联系方式,因此完整性=294 / 300 * 100% = 98%。
2. Uniqueness 唯一性
唯一性表示同样的数据只出现一次,关键在于如何定义两天数据是同样的。
案例:学校有120名在校生和380名已经毕业的学生,总共500名,但是数据库里面有520名不用学生的记录,其中把Fred Smith和Freddy Smith记录成了两个不同的学生,其实是同一个学生,因此唯一性=500 / 520 * 100% = 96.2%
3. Timeliness 时效性
时效性表示数据真实产生到被记录花了多少时间。
案例:Tina Jones在2013年6月1日更新了自己的联系方式,数据库管理员在6月4日记录到了数据库,因此数据延迟了3天。
4. Validity 有效性
有效性表示数据是否符合某种定义的语法,包括格式、类型、范围。
案例:全国所有学校每个班级需要定义一个ID,包括班主任的3个英文字母缩写和表示年份的两个数字,例如:AAA99。某年来了个新老师Sally Hearn,没有middle name,因此无法用三个字母来表示。
5. Accuracy 精确性
精确性表示数据描述真实时间的正确程度。
案例:欧洲日期格式为DD/MM/YYYY,而美国的日期格式是MM/DD/YYYY,一个美国的学生出生于2000年5月8日,在欧洲读书时由于日期格式问题,会被认为出生于2000年8月5日。
6. Consistency 一致性
一致性表示存在两个或多个数据能描述同一个事物,这些数据描述的结果应该是没有差异的。
案例:学生的出生日期在学校登记处和学校数据库里面的信息是一致的。
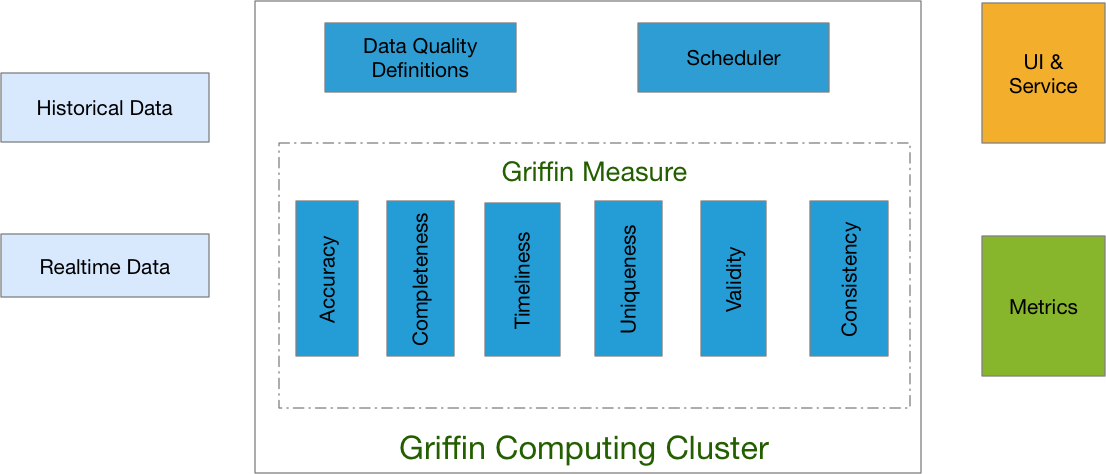
How - Apache Griffin
Apache Griffin是eBay开源的监控数据质量的软件,目前还在Apache孵化。
Apache Griffin基于hadoop和spark,即能监控batch数据也能监控streaming数据,目前提供以下一些功能:
- Accuracy 精确性 - 数据是否正确描述了真实时间的事物
- Completeness 完整性 - 必要的数据是否存在
- Validity 有效性 - 所有数据值都在业务指定的数据域内吗
- Timeliness 时效性 - 数据是否在被需要的时候就存在
- Anomaly detection 异常检测 - 内置了一些算法用于检测数据是否符合预期
- Data Profiling 数据分析 - 提供数据统计以及验证数据一致性和唯一性
参考
Written on April 17, 2018