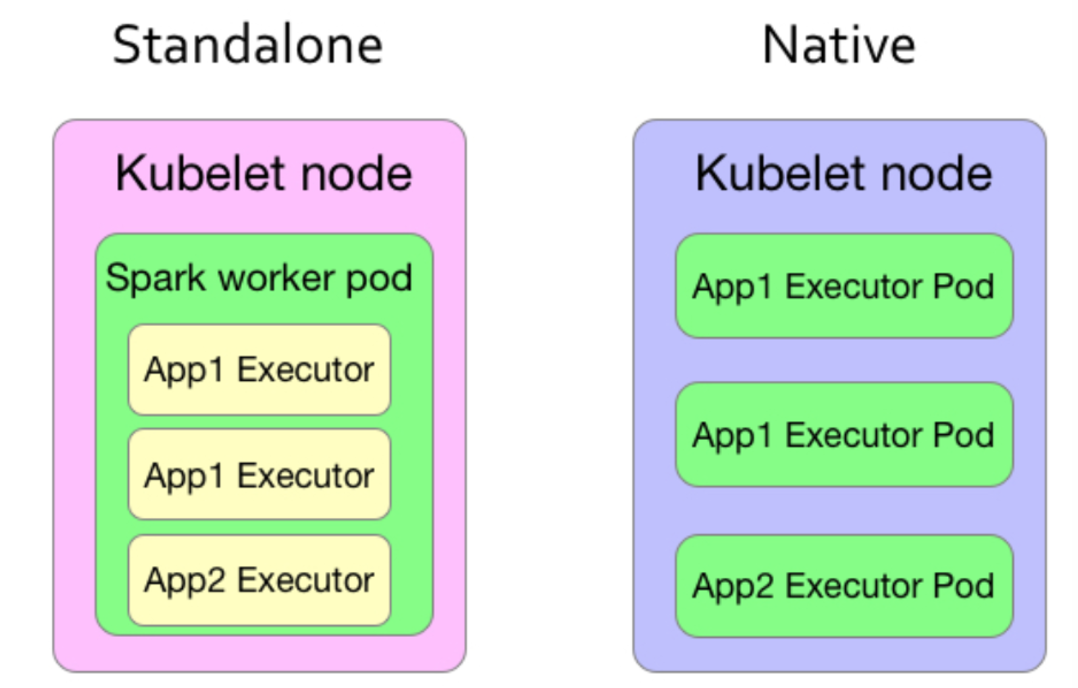
Spark on Kubernetes有两种方案:
- Standalone模式:将Spark的Master和Worker部署到K8s的Pod中,构建一个Spark Standalone集群,对外提供一个master的地址,用户可以像使用一个普通的Standalone集群一样使用,这种模式不需要Spark修改代码,只需要额外提供部署到k8s上的脚本
- Native模式:Spark的每个Executor独立部署到一个Pod,需要修改Spark代码,Spark Driver使用Kubernetes的API进行资源申请
spark standalone on kubernetes 有如下几个缺点:
- 无法对于多租户做隔离,每个用户都想给 pod 申请 node 节点可用的最大的资源。
- Spark 的 master/worker 本来不是设计成使用 kubernetes 的资源调度,这样会存在两层的资源调度问题,不利于与 kuberentes 集成。
Native方式有很多优势:
- Kubernetes原生调度:不再需要二层调度,直接使用kubernetes的资源调度功能,跟其他应用共用整个kubernetes管理的资源池
- 资源隔离,粒度更细:原先yarn中的queue在spark on kubernetes中已不存在,取而代之的是kubernetes中原生的namespace,可以为每个用户分别指定一个namespace,限制用户的资源quota
- 细粒度的资源分配:可以给每个spark任务指定资源限制,实际指定多少资源就使用多少资源,因为没有了像yarn那样的二层调度(圈地式的),所以可以更高效和细粒度的使用资源
所有这些变革都可以让我们更高效的获取资源、更有效率的获取资源!
Spark Standalone on Kubernetes
Spark Standalone on Kubernetes可以参考Charts的实现。
- Spark Master Service:开启7077端口,用于提交Spark任务
- Spark WebUI Service:开启8080端口,用于访问Master Web页面
- Spark Master Deployment:启动一个Spark Master
- Spark Worker Deployment:启动多个Spark Worker,通过Master Service找到Master
Spark Native on Kubernetes
Spark-2.3.0中开始支持原生方式运行到Kubernetes集群,但是只支持cluster方式运行,且还不支持动态扩缩容。
从这篇设计文档SPIP: Support native submission of spark jobs to a kubernetes cluster,我们先来窥探一下Spark Native on Kubernetes的总体设计思路。
资源调度
调用Kubernetes API获取集群资源,一个Executor运行到一个Pod中,调度器负责管理Pod
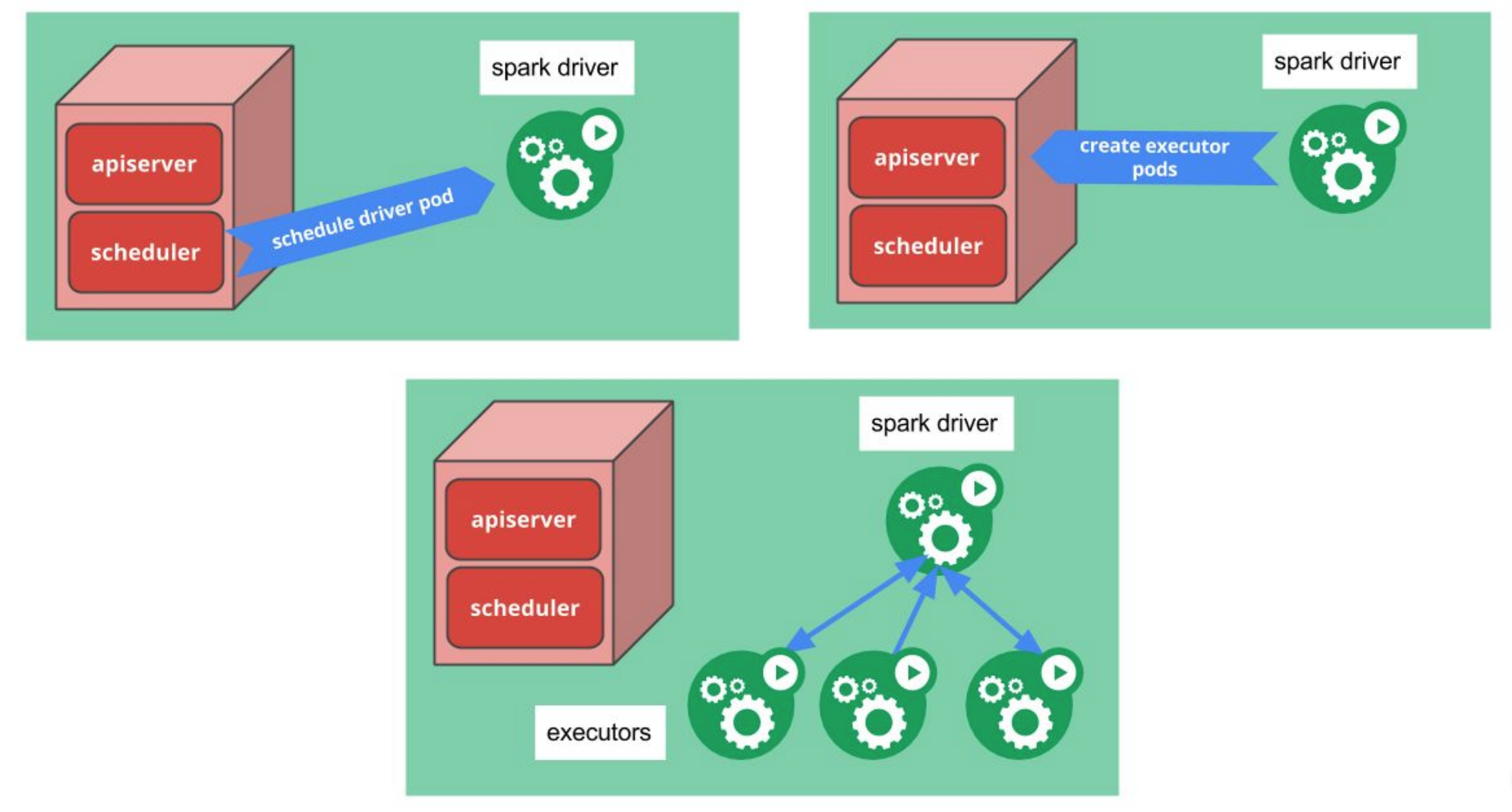
资源获取
提供三种方式获取到用户资源:
- 打包到docker镜像中
- 通过url远程获取,支持http://、s3://、hdfs://
- 运行时把本地资源上传到driver和executor的pod中
本地资源访问是通过Resource Staging Server(RSS)来实现的:
- RSS是独立运行在Kubernetes上的服务
- spark-submit将本地资源上传到RSS
- driver和executor pod从RSS上下载本地资源
External Shuffle Service
为了支持动态扩缩容,需要提供External Shuffle Service,负责保存executor的shuffle数据,可能的实现方式:
- DaemonSet方式在每个节点上运行Shuffle Service服务
- 位于用一个node上的executor和shuffle service使用hostpath volumn共享shuffle数据
- 需求考虑External shuffle service权限问题,同一Spark任务的executor能互相访问
- Shuffle data权限问题,同一Spark任务的pod能访问node上的数据
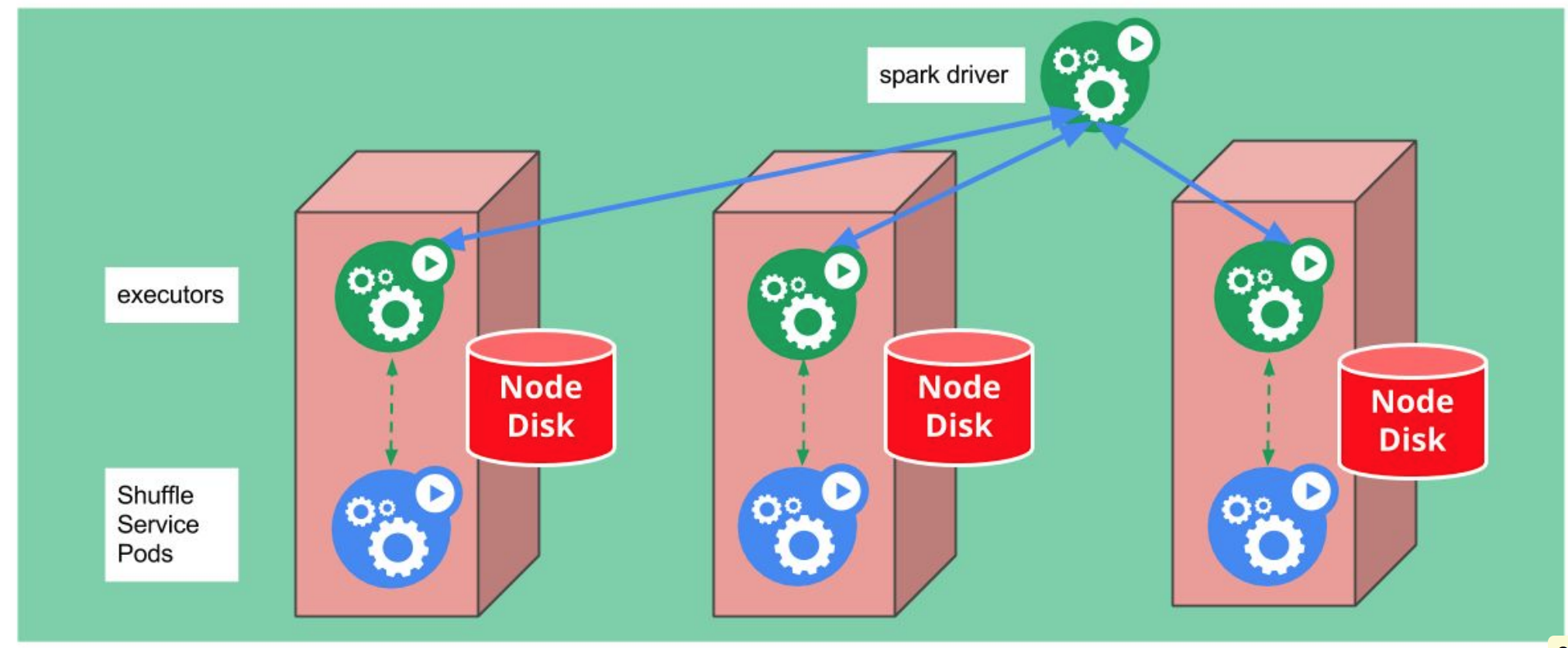
CustomResources
通过CustomResources可以把Spark的API以Kubernetes API的方式暴露出来,用户可以通过kubectl命令控制Spark任务和获取任务状态,同时Kubernetes Dashboard上也可以展示Spark应用状态。
访问Secure HDFS
架构
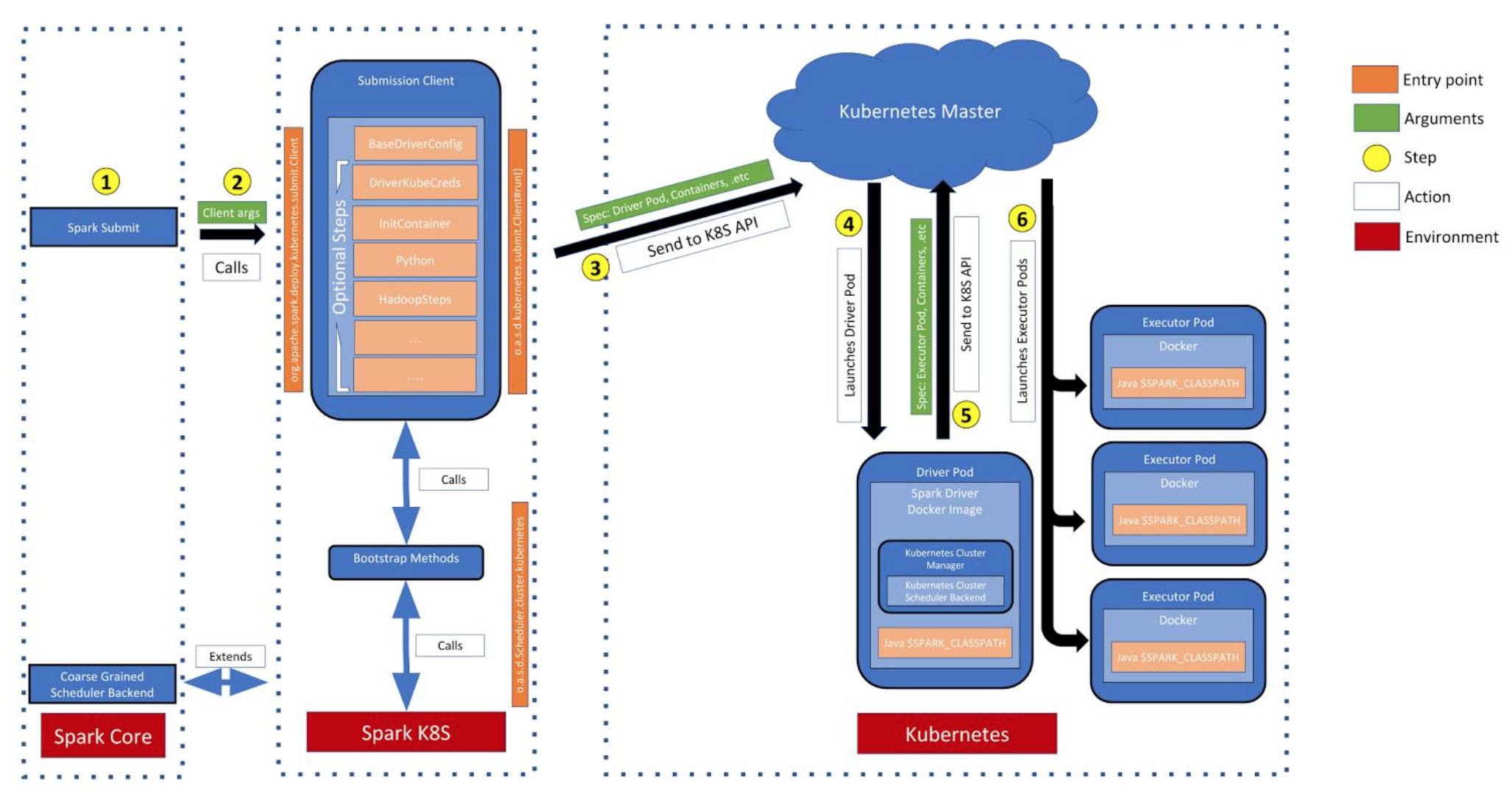
参考
- Spark官方文档
- Spark standalone on Kubernetes
- 运行支持kubernetes原生调度的Spark程序
- Kubernetes与云原生应用概览
- Spark Standalone on k8s
- SPIP: Support native submission of spark jobs to a kubernetes cluster
Written on April 27, 2018