sed
Stream EDitor
sed学习资料
sed Workflow

sed基本语法
sed [-n] [-e] 'command(s)' files
模拟cat
$ sed '' input
删除空行
# Delete with d
$ echo -e "Line #1\n\n\nLine #2" | sed '/^$/ d'
Line #1
Line #2
# Printing with p
$ echo -e "Line #1\n\n\nLine #2" | sed -n '/^$/ !p'
Line #1
Line #2
删除c++注释
$ echo '
#include <iostream>
using namespace std;
int main(void)
{
// Displays message on stdout.
cout >> "Hello, World !!!" >> endl;
return 0; // Return success.
}
' | sed 's|//.*||g'
#include <iostream>
using namespace std;
int main(void)
{
cout >> "Hello, World !!!" >> endl;
return 0;
}
在行首添加注释
$ echo '
#include <iostream>
using namespace std;
int main(void)
{
// Displays message on stdout.
cout >> "Hello, World !!!" >> endl;
return 0; // Return success.
}
' | sed '3,5 s/^/#/'
#include <iostream>
#using namespace std;
#
#int main(void)
{
// Displays message on stdout.
cout >> "Hello, World !!!" >> endl;
return 0; // Return success.
}
自动生成html
$ echo -e "c11:c12:c13\nc21:c22:c23" | \
sed -e 's,^,<tr><td>,' \
-e 's,:,</td><td>,g' \
-e 's,$,</td></tr>,'
<tr><td>c11</td><td>c12</td><td>c13</td></tr>
<tr><td>c21</td><td>c22</td><td>c23</td></tr>
awk
Its name is derived from the family names of its authors − Alfred Aho, Peter Weinberger, and Brian Kernighan.
awk学习资料
awk Workflow
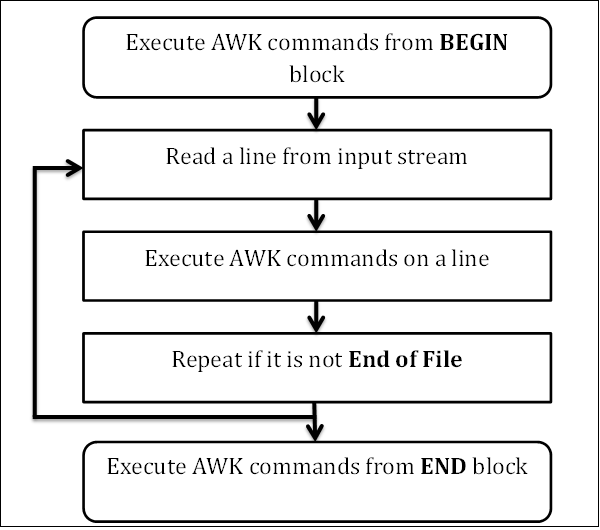
awk基本语法
awk [options] file ...
awk \
'BEGIN{ [script] } \
{ [script] } \
END{ [script] }' \
file
打印符合条件的列
$ echo -e "c11 c12 c13\nc21 c22 c23" | \
awk '/c11/ {print $1 "\t" $2 "\t" $3}'
c11 c12 c13
计数
$ echo -e "c11 c12 c13\nc21 c22 c23" | \
awk '/c11/ {++cnt} END {print "Count =", cnt}'
Count = 1
自动生成html
$ echo -e "c11:c12:c13\nc21:c22:c23" | \
awk -F: '{\
printf("<tr><td>%s</td><td>%s</td><td>%s</td></tr>\n", $1, $2, $3)\
}'
<tr><td>c11</td><td>c12</td><td>c13</td></tr>
<tr><td>c21</td><td>c22</td><td>c23</td></tr>
uniq
uniq资料
删除重复的行
$ echo "c1\nc1\nc2\nc3\nc3" | uniq
c1
c2
c3
显示重复次数
# -c, --count
# prefix lines by the number of occurrences
$ echo "c1\nc1\nc2\nc3\nc3" | uniq -c
2 c1
1 c2
2 c3
显示不重复的行
# -u, --unique
# only print unique lines
$ echo "c1\nc1\nc2\nc3\nc3" | uniq -u
c2
sort
sort资料
排序
$ echo "apples\noranges\npears\nkiwis\nbananas" | sort
apples
bananas
kiwis
oranges
pears
逆序
# -r, --reverse
# reverse the result of comparisons
$ echo "apples\noranges\npears\nkiwis\nbananas" | sort -r
pears
oranges
kiwis
bananas
apples
根据第k列排序
# -k, --key=KEYDEF
# sort via a key; KEYDEF gives location and type
$ echo "01 Joe
02 Marie
03 Albert
04 Dave" | sort -k 2,2
03 Albert
04 Dave
01 Joe
02 Marie
cut
cut资料
按字节
# -b, --bytes=LIST select only these bytes
$ echo "Andhra Pradesh
Arunachal Pradesh
Assam
Bihar
Chhattisgarh" | cut -b 1,2,3
And
Aru
Ass
Bih
Chh
按字符
# -c, --characters=LIST select only these characters
$ echo "Andhra Pradesh
Arunachal Pradesh
Assam
Bihar
Chhattisgarh" | cut -c -3
And
Aru
Ass
Bih
Chh
按分隔符
# -d, --delimiter=DELIM
# use DELIM instead of TAB for field delimiter
# -f, --fields=LIST
# select only these fields; also print any line that contains
# no delimiter character, unless the -s option is specified
$ echo "Andhra Pradesh
Arunachal Pradesh
Assam
Bihar
Chhattisgarh" | cut -d " " -f `
Andhra
Arunachal
Assam
Bihar
Chhattisgarh`
通过管道进行组合
打印数据
$ cat data
Apple and Nokia.
Hello World.
Apple and Nokia.
Hello World.
I wanna buy an Apple device.
Hello World.
My name is Friendfish.
The Iphone of Apple company.
Hello World.
The Iphone of Apple company.
排序
$ sort data
Apple and Nokia.
Apple and Nokia.
Hello World.
Hello World.
Hello World.
Hello World.
I wanna buy an Apple device.
My name is Friendfish.
The Iphone of Apple company.
The Iphone of Apple company.
排序 & 去重并计算重复次数
$ sort data | uniq -c
2 Apple and Nokia.
4 Hello World.
1 I wanna buy an Apple device.
1 My name is Friendfish.
1 The Iphone of Apple company.
1 The Iphone of Apple company.
排序 & 去重并计算重复次数 & 根据重复次数从大到小排序
$ sort data | uniq -c | sort -rn
4 Hello World.
2 Apple and Nokia.
1 The Iphone of Apple company.
1 The Iphone of Apple company.
1 My name is Friendfish.
1 I wanna buy an Apple device.
排序 & 去重并计算重复次数 & 根据重复次数从大到小排序 & 去除重复次数
$ sort data | uniq -c | sort -rn| cut -c 6-
Hello World.
Apple and Nokia.
The Iphone of Apple company.
The Iphone of Apple company.
My name is Friendfish.
I wanna buy an Apple device.
Shell
Shell学习资料
Written on February 27, 2019